
AIやデータ活用は、基本情報技術者試験でも出題される重要分野です。
ただし、基本情報技術者試験では「AIは便利な技術です」といった浅い理解だけでは足りません。
AIやデータ活用の基礎から確認したい方は、先にITパスポートのAI・データ活用対策を読むと、AI、生成AI、IoT、DXのつながりを整理しやすくなります。
どんな目的で、どんなデータを使い、どの方法で学習し、結果をどう評価するのかを見分ける力が必要です。
科目Aと科目Bで問われる力の違いを確認したい方は、基本情報技術者試験の科目Aと科目Bの違いも参考にしてください。
ここだけ読めばOK
AI・データ活用では、まず「何をしたいのか」を見ます。種類を分けるなら分類、数値を予測するなら回帰、正解なしで似たものを分けるならクラスタリングです。
この記事では、基本情報技術者試験で押さえたいAI、機械学習、教師あり学習、教師なし学習、分類、回帰、クラスタリング、前処理、評価を、初心者向けに整理して解説します。
基本情報技術者試験のAI・データ活用では何を学ぶ?
基本情報技術者試験のAI・データ活用では、AIの使い方だけでなく、データを使ってどのように判断するのかが問われます。
特に、機械学習の種類、分類と回帰の違い、データ分析の流れは押さえておきたい内容です。
AIや機械学習の基本が問われる
AIは、人の知的な作業をコンピューターで助けるための技術です。
AIの意味を先に確認したい方は、AIとはも参考になります。
たとえば、画像を見分ける、文章を作る、音声を文字にする、売上を予測する、異常を見つけるといった場面で使われます。
その中でも、機械学習は、データからパターンを学ぶ方法です。
基本情報技術者試験では、AI、機械学習、ディープラーニングの関係を見分ける問題が出やすいです。
分類や回帰などの違いが問われる
機械学習では、目的によって使う方法が変わります。
迷惑メールかどうかを分けるなら「分類」です。
来月の売上を予測するなら「回帰」です。
このように、問題文を読んで「種類を分けたいのか」「数値を予測したいのか」を見分けることが大切です。
データ分析の流れが問われる
データ分析では、いきなりAIにデータを入れるわけではありません。
まず目的を決め、データを集め、データを整え、分析し、結果を評価します。
特に、欠けたデータやおかしな値を整える「前処理」は大切です。
前処理が不十分だと、AIや分析の結果がずれることがあります。
基本情報技術者試験で押さえるAI・データ活用の全体像
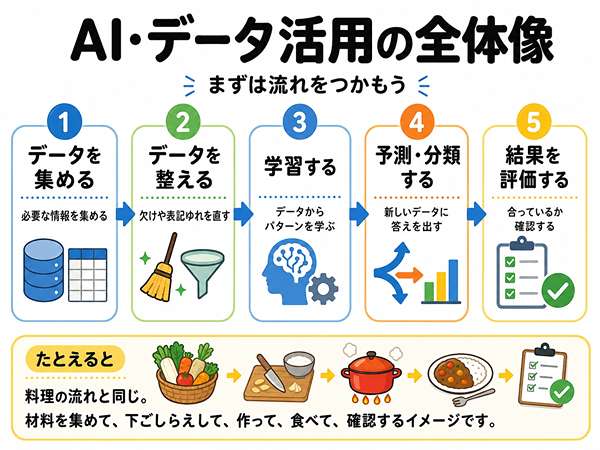
AI・データ活用は、次の流れで考えると分かりやすくなります。
| 流れ | 内容 | 見るポイント |
|---|---|---|
| データを集める | 分析に使う情報を用意する | 目的に合うデータか |
| データを整える | 欠けや表記ゆれを直す | 前処理が必要か |
| 学習する | データからパターンを学ぶ | 正解付きかどうか |
| 予測や分類をする | 新しいデータに答えを出す | 種類か数値か |
| 結果を評価する | 結果が正しいか確認する | 過学習していないか |
データを集める
まず、目的に合うデータを集めます。
売上を予測したいなら、過去の売上、時期、広告、天気、キャンペーンなどが関係するかもしれません。
迷惑メールを見分けたいなら、過去のメール本文、送信元、件名、リンクの有無などが使われます。
データは多ければよいとは限りません。目的に合うデータを集めることが大切です。
データを整える
集めたデータは、そのままでは使いにくいことがあります。
空欄がある、表記がばらばら、極端におかしな値がある、といった問題があるからです。
このようなデータを使いやすく整える作業を、前処理といいます。
データの誤りや表記ゆれなどを直す作業は、データクレンジングと呼ばれることもあります。
学習する
機械学習では、用意したデータを使って、コンピューターがパターンを学びます。
迷惑メールの例では、過去のメールから「迷惑メールに多い特徴」を学びます。
売上予測の例では、過去の売上と条件の関係を学びます。
予測や分類をする
学習したあとは、新しいデータに対して結果を出します。
新しいメールを見て「迷惑メール」か「通常メール」かを分けるのが分類です。
来月の売上がいくらになりそうかを出すのが回帰です。
結果を評価する
AIが出した結果は、必ず確認します。
学習したデータだけに強く、新しいデータに弱い状態もあります。
この状態を過学習といいます。
基本情報技術者試験では、学習用データとテスト用データを分ける理由も押さえておきましょう。
AIと機械学習の関係とは?
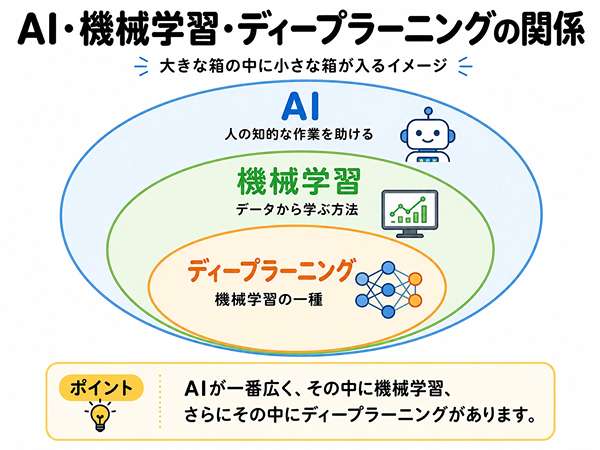
AI、機械学習、ディープラーニングは、似た言葉として出てきます。
混同しやすいですが、範囲の広さが違います。
AIは人の知的な作業を助ける技術
AIは、人工知能とも呼ばれます。
人が考えて行うような作業を、コンピューターで助ける技術です。
たとえば、次のようなものがあります。
- 画像を見て何が写っているか判断する
- 文章を要約する
- 音声を文字に変える
- 売上や需要を予測する
- 異常なデータを見つける
AIは広い言葉です。機械学習やディープラーニングも、AIに関係する技術です。
機械学習はデータからパターンを学ぶ方法
機械学習は、データからパターンを見つける方法です。
人がすべてのルールを細かく書かなくても、コンピューターがデータから関係を学びます。
たとえると
機械学習は、たくさんの例を見てコツを覚えるようなものです。迷惑メールの例を多く見ることで、「こういうメールは迷惑メールらしい」と判断できるようになります。
ディープラーニングは機械学習の一種
ディープラーニングは、機械学習の一種です。
大量のデータから、複雑な特徴を学ぶのに使われます。
画像認識、音声認識、自然言語処理などで使われます。
基本情報技術者試験では、ディープラーニングを「AIそのもの」と考えないように注意しましょう。
AI・機械学習・ディープラーニングの違い
| 用語 | 意味 | 関係 |
|---|---|---|
| AI | 人の知的な作業を助ける技術 | 一番広い |
| 機械学習 | データからパターンを学ぶ方法 | AIの中の一つ |
| ディープラーニング | 複雑な特徴を学ぶ機械学習の方法 | 機械学習の中の一つ |
見分け方は、次の通りです。
- 人の知的作業を助ける広い技術ならAI
- データからパターンを学ぶなら機械学習
- 機械学習の中で、深い層を使う方法ならディープラーニング
機械学習の基本の流れ
機械学習は、データを用意して学習し、新しいデータに対して予測する流れで考えます。
基本情報技術者試験では、流れを順番で押さえることが大切です。
データを用意する
まず、学習に使うデータを用意します。
分類なら、過去のデータとその種類を用意することがあります。
回帰なら、過去の数値データを用意することがあります。
売上予測なら、過去の売上や月ごとの条件を集めます。
学習用データで学ぶ
学習用データは、機械学習モデルにパターンを学ばせるためのデータです。
モデルとは、入力されたデータから結果を出す仕組みのことです。
迷惑メール判定では、学習用データから「迷惑メールに多い特徴」を学びます。
テスト用データで確認する
学習したモデルは、テスト用データで確認します。
テスト用データは、学習には使わず、結果を確かめるために使うデータです。
これにより、新しいデータにも対応できるかを確認できます。
新しいデータに対して予測する
学習と確認ができたら、新しいデータに対して予測します。
新しいメールが迷惑メールかどうかを判定する。
来月の売上を予測する。
このように、目的に応じて結果を出します。
結果を評価して改善する
予測結果がいつも正しいとは限りません。
結果を評価し、必要に応じてデータや方法を見直します。
基本情報技術者試験では、「学習して終わり」ではなく「評価して改善する」と覚えておきましょう。
教師あり学習とは?正解付きデータで学ぶ方法
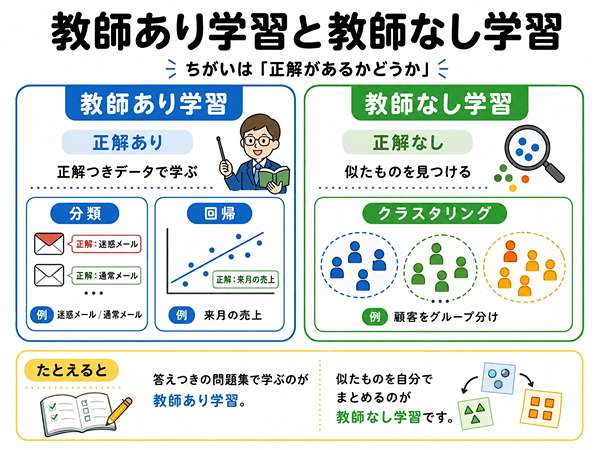
教師あり学習とは、正解付きデータを使って学習する方法です。
ここでいう教師とは、人の先生のことではなく、データに付いた正解のことです。
正解付きデータで学習する
教師あり学習では、入力データと正解をセットで使います。
たとえば、メールの本文と「迷惑メール」「通常メール」という正解をセットにします。
そのデータを学習することで、新しいメールも判定できるようにします。
分類に使われる
分類は、データを種類に分けることです。
分類では、正解付きデータを使うことが多いため、教師あり学習に含まれます。
例として、次のようなものがあります。
- 迷惑メールかどうかを分ける
- 画像を犬か猫かに分ける
- 商品レビューを良い評価・悪い評価に分ける
回帰に使われる
回帰は、数値を予測することです。
回帰も、正解となる数値がある過去データを使って学習するため、教師あり学習に含まれます。
例として、来月の売上、気温、需要、価格などを予測します。
教師あり学習の例
| 目的 | 使うデータ | 方法 |
|---|---|---|
| 迷惑メールを分ける | メール本文と正解ラベル | 分類 |
| 来月の売上を予測する | 過去の売上と条件 | 回帰 |
| 画像を犬・猫に分ける | 画像と正解ラベル | 分類 |
問題で「正解付きデータ」「ラベル付きデータ」と出てきたら、教師あり学習を考えましょう。
教師なし学習とは?正解なしデータから特徴を見つける方法
教師なし学習とは、正解なしデータから特徴やまとまりを見つける方法です。
あらかじめ「これが正解」と教えられていない点が特徴です。
正解なしデータから特徴を見つける
教師なし学習では、正解ラベルがありません。
その代わり、データ同士の似ている点や違いを見つけます。
たとえば、顧客データを見て、買い方が似ている人たちをグループに分けることがあります。
クラスタリングに使われる
教師なし学習の代表例が、クラスタリングです。
クラスタリングは、似たデータをグループに分けることです。
どのグループが正解かを先に決めるのではなく、データの特徴からまとまりを見つけます。
似たもの同士をグループに分ける
クラスタリングでは、似たもの同士を同じグループにします。
たとえば、購買履歴が似ている顧客をグループに分けることができます。
この結果を使って、グループごとにおすすめ商品を変えることもあります。
教師あり学習との違い
| 種類 | 正解ラベル | 代表例 | 見分け方 |
|---|---|---|---|
| 教師あり学習 | ある | 分類、回帰 | 正解付きデータで学ぶ |
| 教師なし学習 | ない | クラスタリング | 正解なしで特徴を見つける |
基本情報技術者試験では、「正解があるかないか」を見ると、教師あり学習と教師なし学習を見分けやすくなります。
分類とは?種類を分けること
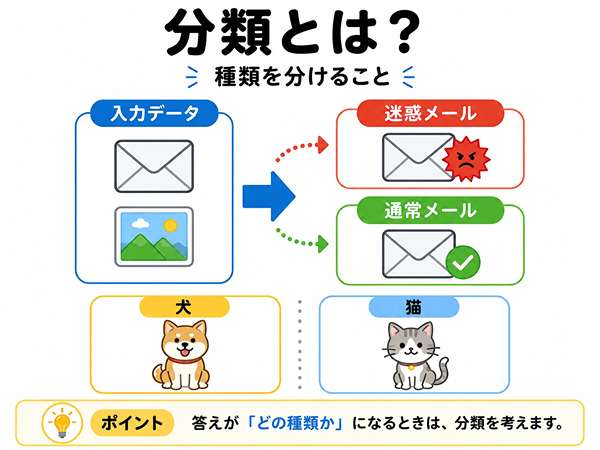
分類とは、データを種類に分けることです。
答えが「どの種類か」になる問題では、分類を考えます。
分類は種類を分けること
分類では、結果がカテゴリになります。
カテゴリとは、種類やグループのことです。
たとえば、「迷惑メール」「通常メール」のように、いくつかの種類に分けます。
試験寄りに言うと、分類はカテゴリを予測する方法です。
迷惑メールかどうかを分ける例
分類の代表例は、迷惑メール判定です。
メールの本文、送信元、件名、リンクの有無などをもとに、迷惑メールかどうかを判断します。
結果は、次のようになります。
- 迷惑メール
- 通常メール
このように、結果が種類で出る場合は分類です。
画像を犬・猫に分ける例
画像を見て、犬か猫かを分けるのも分類です。
結果は「犬」「猫」のような種類です。
数値を予測しているわけではありません。
分類問題で見分けるポイント
分類問題を見分けるポイントは、答えが種類になるかどうかです。
| 問題文の例 | 答え | 方法 |
|---|---|---|
| メールを迷惑メールか通常メールに分ける | 種類 | 分類 |
| 画像を犬・猫に分ける | 種類 | 分類 |
| 顧客が購入するかしないかを判定する | 種類 | 分類 |
「分ける」「判定する」「識別する」といった言葉がある場合は、分類の可能性があります。
回帰とは?数値を予測すること
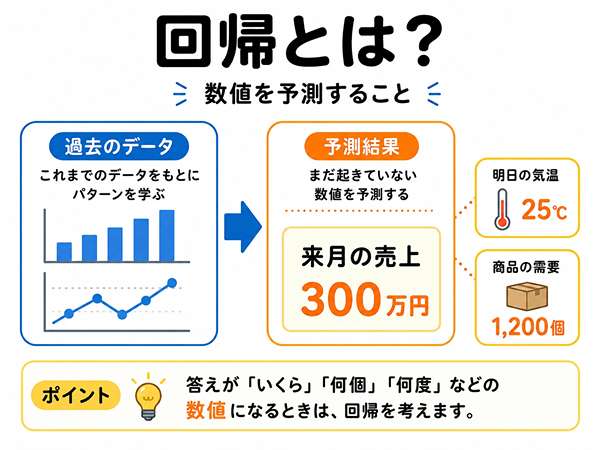
回帰とは、数値を予測することです。
答えが金額、温度、個数、時間などの数値になる場合は、回帰を考えます。
回帰は数値を予測すること
回帰では、過去のデータをもとに、未来や未知の数値を予測します。
結果は「売上がいくら」「気温が何度」「需要が何個」のような数値です。
試験寄りに言うと、回帰は数値を予測する方法です。
来月の売上を予測する例
回帰の代表例は、来月の売上予測です。
過去の売上、季節、広告費、来店数などを使って、来月の売上を予測します。
結果は「来月の売上は300万円の見込み」のような数値になります。
気温や需要を予測する例
気温や商品の需要を予測する場合も、回帰に当てはまります。
たとえば、次のようなものがあります。
- 明日の気温を予測する
- 来週の来店者数を予測する
- 商品の需要数を予測する
- 中古車の価格を予測する
分類との違い
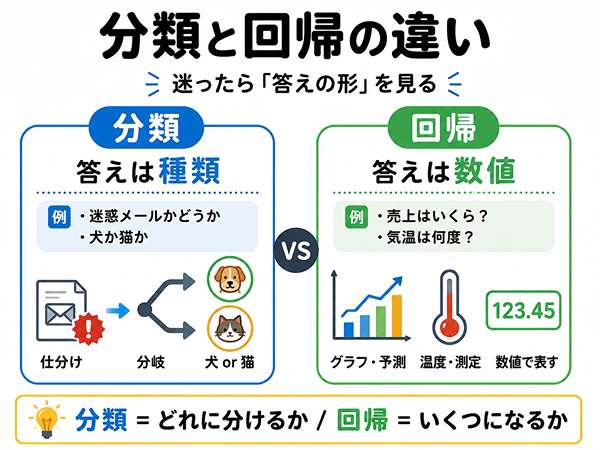
| 項目 | 分類 | 回帰 |
|---|---|---|
| 目的 | 種類を分ける | 数値を予測する |
| 答え | カテゴリ | 数値 |
| 例 | 迷惑メールかどうか | 来月の売上 |
| 見分け方 | どの種類か | いくら、何個、何度か |
一言でいうと
分類は「どれに分けるか」、回帰は「いくつになるか」を求める方法です。
クラスタリングとは?似たデータをグループに分けること
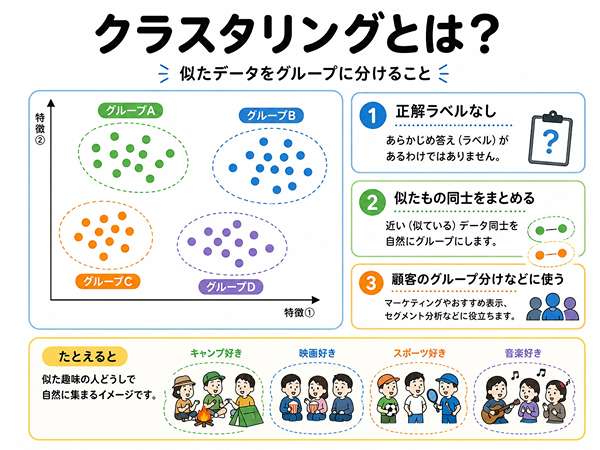
クラスタリングとは、似たデータをグループに分けることです。
分類と似ていますが、正解ラベルがない点が大きく違います。
クラスタリングは似たデータをグループに分けること
クラスタリングでは、データの特徴を見て、似ているもの同士を集めます。
たとえば、顧客の買い方や行動を見て、似た人たちを同じグループにします。
あらかじめ「この人はAグループ」と決まっているわけではありません。
顧客をグループ分けする例
顧客データを使って、購買行動が似ている人を分ける例があります。
たとえば、次のようなグループが見つかるかもしれません。
- 安い商品をよく買う人
- 新商品をよく買う人
- 週末にまとめ買いする人
- 特定の商品だけをよく買う人
このように、データから自然なまとまりを見つけます。
正解ラベルがないときに使う
クラスタリングは、正解ラベルがないときに使います。
つまり、最初から「Aグループ」「Bグループ」と正解が付いているわけではありません。
データの特徴から、似たもの同士をまとめます。
教師なし学習との関係
クラスタリングは、教師なし学習の代表例です。
問題文に「正解ラベルがない」「似たもの同士に分ける」「グループ化する」とあれば、クラスタリングを考えましょう。
AI・データ活用で出るデータ分析の基本
データ分析とは、データを使って状況を理解したり、判断に役立てたりすることです。
AIや機械学習も、データ分析の流れの中で使われることがあります。
目的を決める
最初に、何を知りたいのかを決めます。
目的があいまいだと、どのデータを集めればよいか分かりません。
たとえば、次のように目的を決めます。
- 売上が下がった理由を知りたい
- 来月の需要を予測したい
- 顧客をグループに分けたい
- 不正な取引を見つけたい
データを集める
目的に合わせてデータを集めます。
売上を分析するなら、売上日、商品、価格、数量、顧客情報などが関係します。
目的に関係のないデータを大量に集めても、よい分析になるとは限りません。
前処理をする
集めたデータは、そのまま使えるとは限りません。
空欄、表記ゆれ、重複、おかしな値などを確認します。
この作業が前処理です。
前処理の中でも、データの誤りや表記ゆれを直す作業は、データクレンジングと呼ばれることがあります。
分析する
前処理をしたあと、データを分析します。
集計、グラフ化、分類、回帰、クラスタリングなど、目的に合う方法を使います。
基本情報技術者試験では、目的と方法の組み合わせを見分けることが大切です。
結果を解釈する
分析結果を見て、意味を考えます。
ただし、数字が出たからといって、すぐに正しい結論とは限りません。
データの取り方、前処理、分析方法に問題がないかも確認します。
前処理とは?データを分析しやすく整えること
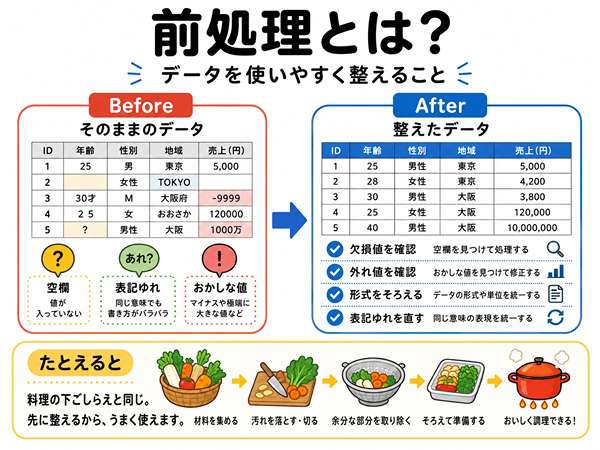
前処理とは、データを分析や学習に使いやすい形に整えることです。
AIやデータ分析では、前処理がとても大切です。
前処理には、欠損値の確認、外れ値の確認、データ形式の統一、表記ゆれの修正などがあります。
欠損値を確認する
欠損値とは、データが欠けている部分のことです。
たとえば、年齢の欄が空白になっている、売上金額が入力されていない、といった状態です。
欠損値が多いと、分析結果がずれることがあります。
外れ値を確認する
外れ値とは、ほかの値と比べて極端に離れた値のことです。
たとえば、通常は数千円の商品なのに、売上金額が99999999円になっている場合などです。
入力ミスの可能性もあるため、確認が必要です。
データ形式をそろえる
データ形式がばらばらだと、正しく分析できません。
たとえば、日付が「2026/5/1」と「2026年5月1日」で混ざっている場合があります。
また、「東京都」「東京」「Tokyo」のように表記が違う場合もあります。
このような表記をそろえることも、前処理です。
前処理が大事な理由
前処理が不十分だと、AIや分析の結果が正しくなくなることがあります。
たとえると、材料が傷んでいるのに料理を作るようなものです。
どれだけよい道具を使っても、元のデータが悪ければ、よい結果は出にくくなります。
評価とは?学習結果が合っているか確認すること
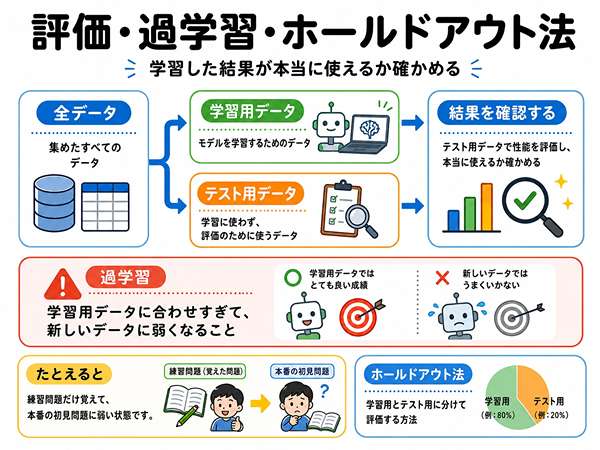
評価とは、学習した結果がどれくらい正しいかを確認することです。
機械学習では、学習して終わりではありません。
学習結果がどれくらい合っているか確認する
モデルが出した結果が、実際の正解にどれくらい合っているかを確認します。
分類なら、正しく分類できた割合などを見ます。
回帰なら、予測した数値と実際の数値のずれを見ます。
ここでは、細かい計算式を覚えるよりも、「結果を確認し、改善につなげる作業」と押さえることが大切です。
学習用データとテスト用データを分ける
学習用データは、モデルに学ばせるために使います。
テスト用データは、学習したモデルを確認するために使います。
同じデータだけで確認すると、本当に新しいデータに強いか分かりません。
そのため、学習用データとテスト用データを分けることが重要です。
学習用データとテスト用データに分けて確認する考え方は、ホールドアウト法と呼ばれることがあります。
過学習に注意する
過学習とは、学習用データに合わせすぎて、新しいデータに弱くなることです。
たとえば、練習問題の答えだけを丸暗記して、少し形が違う問題が解けない状態に似ています。
機械学習でも、学習用データだけに強い状態はよくありません。
評価をして改善につなげる
評価の結果が悪ければ、データや方法を見直します。
データを増やす、前処理を見直す、使う方法を変えるなどの改善が考えられます。
基本情報技術者試験では、評価は「結果を確認して改善するための作業」と押さえましょう。
アルゴリズムとAIの関係とは?
AIや機械学習も、コンピューターが処理を行う以上、アルゴリズムと関係があります。
アルゴリズムは、処理の手順です。
アルゴリズムの基本を確認したい方は、基本情報技術者試験のアルゴリズム対策も参考になります。
アルゴリズムは処理の手順
アルゴリズムとは、目的を達成するための手順です。
たとえば、データを並べ替える、探す、分類する、計算する、といった処理には手順があります。
AIも、入力されたデータをもとに、決められた手順や計算で結果を出します。
機械学習にも手順や計算の考え方がある
機械学習では、データを使ってモデルを作ります。
その中では、データを読み込み、特徴を取り出し、計算し、結果を調整する流れがあります。
つまり、AIは魔法の箱ではなく、データと手順をもとに動いています。
データからルールを見つける
従来のプログラムでは、人がルールを細かく書くことが多いです。
一方、機械学習では、データからルールやパターンを見つけます。
迷惑メール判定では、人がすべての迷惑メールの条件を書くのではなく、過去のメールから特徴を学びます。
AIをブラックボックスにしすぎない
ブラックボックスとは、中で何が起きているか分かりにくい状態のことです。
AIの結果だけを信じるのではなく、どんなデータを使ったのか、どのような目的で使うのか、結果をどう評価したのかを確認することが大切です。
基本情報技術者試験では、AIの便利さだけでなく、データや評価の大切さも問われます。
基本情報技術者試験で間違えやすいAI・データ活用用語
AI・データ活用では、似た用語が多く出てきます。
ここでは、試験で間違えやすい組み合わせを整理します。
AIと機械学習の違い
AIは広い言葉です。
機械学習は、AIを実現するための方法の一つです。
「AI=機械学習」と考えると間違えることがあります。
機械学習とディープラーニングの違い
ディープラーニングは、機械学習の一種です。
つまり、ディープラーニングは機械学習に含まれます。
機械学習のすべてがディープラーニングではありません。
教師あり学習と教師なし学習の違い
教師あり学習は、正解付きデータで学びます。
教師なし学習は、正解なしデータから特徴を見つけます。
問題文に「正解ラベル」「教師データ」とあれば、教師あり学習を考えます。
「似たものをグループ化」「正解がない」とあれば、教師なし学習を考えます。
分類と回帰の違い
分類は、種類を分けることです。
回帰は、数値を予測することです。
迷惑メールかどうかを分けるなら分類です。
来月の売上を予測するなら回帰です。
クラスタリングと分類の違い
クラスタリングと分類は、どちらもグループに関係します。
ただし、分類は正解ラベルがある場合に使われます。
クラスタリングは、正解ラベルがない状態で似たものを分けます。
| 用語 | 見分けるポイント | 例 |
|---|---|---|
| 分類 | 正解ラベルがあり、種類を分ける | 迷惑メールかどうか |
| 回帰 | 数値を予測する | 来月の売上 |
| クラスタリング | 正解なしで似たものを分ける | 顧客のグループ分け |
基本情報技術者試験のAI・データ活用問題の解き方
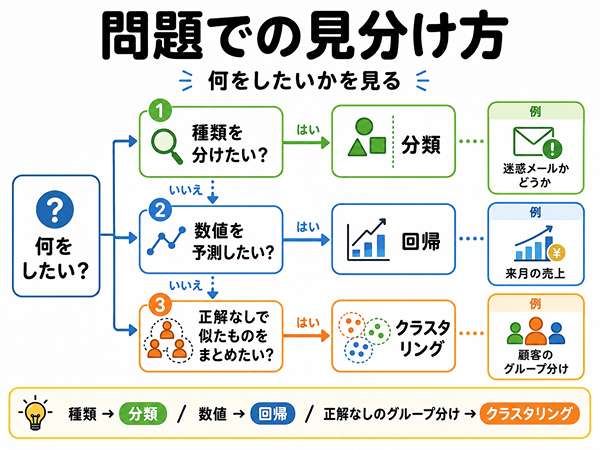
AI・データ活用の問題では、用語を暗記するだけではなく、問題文から目的を読み取ることが大切です。
何をしたい問題か確認する
まず、問題文で何をしたいのかを確認します。
- 種類を分けたいのか
- 数値を予測したいのか
- 似たものをまとめたいのか
- データを整えたいのか
- 結果を評価したいのか
目的が分かると、選ぶ用語も見えやすくなります。
正解付きデータがあるか確認する
次に、正解付きデータがあるかを見ます。
正解付きデータがあるなら、教師あり学習です。
正解がなく、データの特徴からまとまりを見つけるなら、教師なし学習です。
種類を分けるのか、数値を予測するのかを見る
分類と回帰は、答えの形で見分けます。
答えが「種類」なら分類です。
答えが「数値」なら回帰です。
この見分け方は、基本情報技術者試験の問題でとても使いやすいです。
データ分析のどの段階か確認する
問題文が、データ分析のどの段階について聞いているかも確認します。
| 段階 | 内容 | キーワード |
|---|---|---|
| 目的設定 | 何を知りたいか決める | 目的、課題 |
| 収集 | データを集める | 収集、取得 |
| 前処理 | データを整える | 欠損値、外れ値、形式、表記ゆれ |
| 分析・学習 | データから特徴を得る | 分類、回帰、クラスタリング |
| 評価 | 結果を確認する | テスト用データ、過学習、ホールドアウト法 |
選択肢の似た言葉に注意する
基本情報技術者試験では、似た言葉を選択肢に並べてくることがあります。
特に、次の組み合わせに注意しましょう。
- 分類と回帰
- 分類とクラスタリング
- 教師あり学習と教師なし学習
- 機械学習とディープラーニング
- 学習用データとテスト用データ
迷ったら、問題文の「目的」「正解ラベルの有無」「答えの形」を見直しましょう。
基本情報技術者試験ではAI・データ活用がどう出る?
基本情報技術者試験では、AI・データ活用の用語や考え方が、説明文と選択肢の形で出ることがあります。
深い数式よりも、まずは用語の関係と使い分けを押さえることが大切です。
AIや機械学習の用語を問う問題
AI、機械学習、ディープラーニングの関係を問う問題が考えられます。
この場合は、範囲の広さを見ます。
- AIが一番広い
- 機械学習はAIの中の方法
- ディープラーニングは機械学習の一種
教師あり学習と教師なし学習を見分ける問題
教師あり学習と教師なし学習は、正解ラベルの有無で見分けます。
正解付きデータで学ぶなら、教師あり学習です。
正解なしで似たものを見つけるなら、教師なし学習です。
分類と回帰を見分ける問題
分類と回帰は、答えの形で見分けます。
迷惑メールかどうかを分けるなら分類です。
来月の売上を予測するなら回帰です。
「種類」か「数値」かを見るのがポイントです。
データ分析の流れを問う問題
データ分析の流れも問われます。
目的を決め、データを集め、前処理をし、分析し、結果を評価する流れです。
特に、前処理と評価の役割を押さえておくと、選択肢を選びやすくなります。
アルゴリズムとの関係を問う問題
AIや機械学習は、データと手順をもとに動きます。
AIだからといって、理由なく答えが出ているわけではありません。
データ、手順、評価の考え方があると押さえましょう。
AI・データ活用の確認問題
最後に、基本情報技術者試験でよく問われる考え方を確認しましょう。
教師あり学習と教師なし学習の違いは何ですか?
教師あり学習は、正解付きデータで学習する方法です。
分類や回帰に使われます。
教師なし学習は、正解なしデータから特徴やまとまりを見つける方法です。
クラスタリングに使われます。
分類と回帰の違いは何ですか?
分類は、種類を分けることです。
例として、迷惑メールかどうかを分ける場合があります。
回帰は、数値を予測することです。
例として、来月の売上を予測する場合があります。
前処理はなぜ必要ですか?
前処理は、データを分析や学習に使いやすい形に整えるために必要です。
欠損値、外れ値、表記ゆれ、形式の違いなどをそのままにすると、分析結果がずれることがあります。
そのため、AIやデータ分析では、前処理が重要です。
まとめ:AI・データ活用は学習方法・分類・回帰の違いを整理しよう
基本情報技術者試験のAI・データ活用では、AIを便利な道具として見るだけでなく、データを使ってどのように学習し、予測し、評価するのかを理解することが大切です。
まず、AI、機械学習、ディープラーニングの関係を押さえましょう。
次に、教師あり学習と教師なし学習の違いを、正解ラベルの有無で見分けます。
分類と回帰は、答えの形で見分けます。
- 分類:種類を分ける
- 回帰:数値を予測する
- クラスタリング:正解なしで似たものを分ける
- 前処理:データを使いやすく整える
- データクレンジング:データの誤りや表記ゆれを直す
- 評価:結果がどれくらい合っているか確認する
- 過学習:学習用データに合わせすぎて、新しいデータに弱くなること
基本情報技術者試験の問題では、用語そのものよりも「何をしたいのか」が大事です。
問題文を読んだら、まず目的を確認しましょう。
種類を分けるのか、数値を予測するのか、正解ラベルがあるのかを見ることで、選択肢を選びやすくなります。
AI・データ活用を含めた基本情報全体の進め方は、基本情報技術者試験の勉強方法も参考にしてください。