
基本情報技術者試験の科目Bでは、アルゴリズムの考え方がとても大切です。
科目B全体の進め方を先に確認したい方は、基本情報技術者試験の科目B対策も参考にしてください。
アルゴリズムとは、かんたんに言うと「問題を解くための手順」です。
たとえば、料理にはレシピがあります。材料を切る、火を通す、味をつける、盛りつける。このように、目的を達成するためには順番があります。
プログラムも同じです。コンピューターは、決められた手順にそって、1つずつ処理を進めます。
この記事では、基本情報技術者試験で学ぶアルゴリズムの全体像をやさしく整理します。
いきなり難しい疑似言語や計算から入るのではなく、「何を学ぶのか」「なぜ学ぶのか」「どの順番で学ぶとよいのか」を順番に見ていきます。
この記事の目的は、アルゴリズムを暗記することではありません。処理の流れを1つずつ追えるようになることです。
基本情報技術者試験のアルゴリズムは何を学ぶ分野?
基本情報技術者試験のアルゴリズムでは、プログラムがどのような順番で動くのかを学びます。
プログラムは、基本的には上から順番に処理されます。
ただし、途中で条件によって進む道が変わったり、同じ処理を何度もくり返したりします。
その流れを読めるようにすることが、アルゴリズム学習の大きな目的です。
科目Bで特に重要な分野
基本情報技術者試験の科目Bでは、単語の意味を知っているだけでは解けない問題が出ます。
特に大切なのは、次のような内容です。
- 変数の値がどう変わるか
- 条件によって処理がどう分かれるか
- くり返し処理が何回行われるか
- 配列のどの位置を見ているか
- 探索やソートの途中でデータがどう変わるか
つまり、アルゴリズムでは「知っているか」よりも「処理を追えるか」が大切です。
暗記よりも処理の流れを追う力が大事
アルゴリズムと聞くと、難しい公式や計算を覚えるものだと思うかもしれません。
しかし、基本情報技術者試験の学習では、最初から難しい話に進む必要はありません。
まず大事なのは、次のように1つずつ確認することです。
- 今、どの処理をしているか
- 今、どの値を見ているか
- 処理のあと、値がどう変わったか
- 次にどこへ進むか
この確認ができるようになると、疑似言語の問題も読みやすくなります。
疑似言語を読めるようになることが目標
基本情報技術者試験では、特定のプログラミング言語ではなく、疑似言語で処理が書かれます。
疑似言語とは、プログラムの考え方を読みやすく書いたものです。
たとえば、次のように値を変数に入れます。
合計 ← 0この「←」は、右側の値を左側の変数に入れるという意味です。
上の例では、「0を合計に入れる」という意味になります。
最初は記号にとまどうかもしれませんが、1行ずつ読めば大丈夫です。
疑似言語の読み方とトレースの基本は、基本情報技術者試験の疑似言語とトレース入門でくわしく解説しています。
かんたんに言うと、アルゴリズムは問題を解く手順
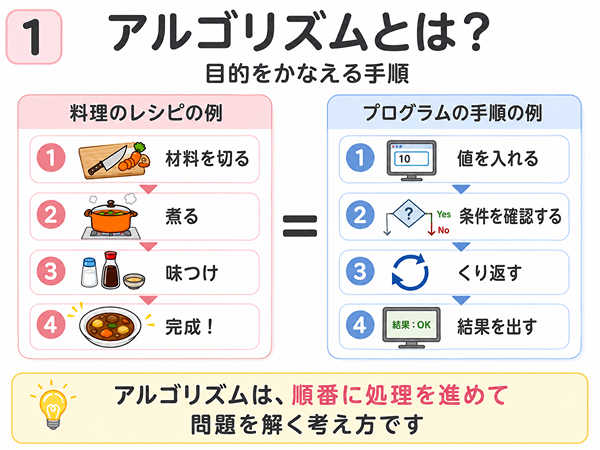
アルゴリズムは、問題を解くための手順です。
たとえば、次のような処理にも手順があります。
- 点数の一覧から一番高い点を探す
- 商品を安い順に並べる
- 会員番号から会員情報を探す
- 予約一覧から空いている時間を探す
コンピューターは、何となく判断しているわけではありません。
決められた手順にしたがって、1つずつ処理しています。
料理のレシピのように順番がある
アルゴリズムは、料理のレシピに似ています。
カレーを作る場合、いきなりルーを入れるのではなく、野菜を切る、炒める、水を入れる、煮る、ルーを入れる、という順番があります。
順番を間違えると、うまく作れないことがあります。
プログラムも同じです。
先に準備する値、あとで使う値、くり返す処理には、きちんとした順番があります。
同じ目的でも手順はいくつかある
同じ目的でも、手順は1つとは限りません。
たとえば、商品を探すとき、1件ずつ上から見る方法があります。
一方で、データが順番に並んでいれば、探す範囲を半分ずつしぼる方法もあります。
データを並べるときも、となり同士を比べる方法、最小の値を探して前に置く方法、分けてからまとめる方法などがあります。
目的が同じでも、使う手順によって動きは変わります。
手順が変わると速さや分かりやすさも変わる
手順が変わると、処理の速さや分かりやすさも変わります。
たとえば、10件のデータなら、上から順番に探してもあまり困りません。
しかし、100万件のデータを毎回1件ずつ探すと、時間がかかります。
そのため、データの数や並び方に合わせて、使いやすい手順を選ぶことが大切です。
なぜアルゴリズムを学ぶの?
アルゴリズムを学ぶ理由は、プログラムの動きを読めるようにするためです。
基本情報技術者試験では、プログラムを作る力だけでなく、書かれた処理を読んで結果を考える力が問われます。
プログラムの動きを読めるようにするため
プログラムは、変数、条件分岐、くり返し、配列などを組み合わせて動きます。
それぞれの意味を知っていても、処理の流れを追えないと答えにたどり着きにくくなります。
たとえば、次のような処理を見てみます。
合計 ← 0
合計 ← 合計 + 5
合計 ← 合計 + 3最初に、合計には0が入ります。
次に5を足すので、合計は5になります。
さらに3を足すので、合計は8になります。
このように、1行ごとに値の変化を見ていくことが大切です。
基本情報技術者試験の科目Bで処理を追うため
科目Bでは、疑似言語を読んで、処理後の値を選ぶ問題があります。
問題文には、変数、配列、くり返し、条件分岐が組み合わされて出てきます。
そのため、頭の中だけで何となく読むと、途中で値を見失いやすくなります。
紙に書いて、今の値を1つずつ追う練習が大切です。
身近なITサービスの裏側を理解するため
アルゴリズムは、試験のためだけのものではありません。
検索、並べ替え、地図の道順、ゲームの動き、AIのデータ処理など、身近なITサービスの裏側でも使われています。
アルゴリズムを学ぶと、ITサービスがどう動いているのかをイメージしやすくなります。
アルゴリズムは身近で何に使われる?
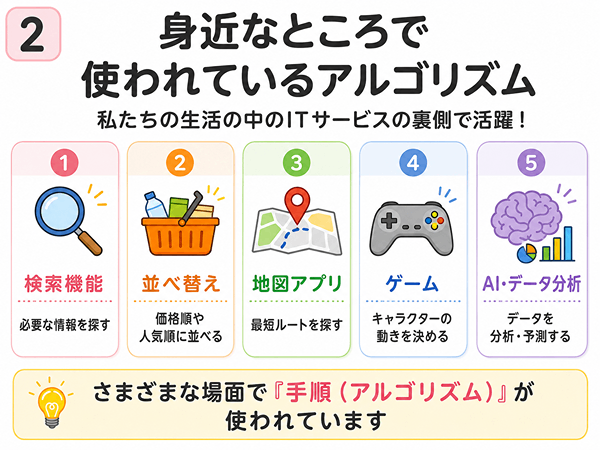
アルゴリズムは、毎日使っているアプリやWebサービスの中にもあります。
ここでは、身近な例で見ていきます。
検索機能で目的の情報を探す
検索機能では、たくさんのデータの中から、条件に合うものを探します。
たとえば、会員番号から会員を探す、商品名から商品を探す、ファイル名からファイルを探す、といった処理です。
このような「探す処理」は、探索アルゴリズムの考え方と関係します。
商品一覧を価格順や人気順に並べる
ネットショップでは、商品を価格順、人気順、更新日順に並べ替えられます。
この「並べる処理」は、ソートアルゴリズムの考え方です。
ただ並べているだけに見えますが、裏側ではデータを比べる処理が行われています。
地図アプリで道順を探す
地図アプリでは、出発地から目的地までの道順を探します。
道路や駅をつながりとして考え、どの道を通るとよいかを調べます。
ここでは、グラフという考え方も関係します。
グラフとは、点と線でつながりを表すデータの持ち方です。
地図、路線図、SNSのつながりなどで使われます。
ゲームでキャラクターの動きを決める
ゲームでは、キャラクターの動きにも手順があります。
敵に近づく、障害物をよける、アイテムを取る、体力が少ないときに逃げるなど、条件に合わせて動きが変わります。
これは、条件分岐や探索の考え方と関係します。
AIやデータ分析でも手順の考え方が使われる
AIやデータ分析でも、データを集める、整える、比べる、学習する、結果を出す、という手順があります。
内容は高度でも、基本にあるのは「どの順番で処理するか」という考え方です。
アルゴリズムの基礎を理解しておくと、あとからAIやデータ分析の話も理解しやすくなります。
基本情報技術者試験で先に理解したい6つの基本
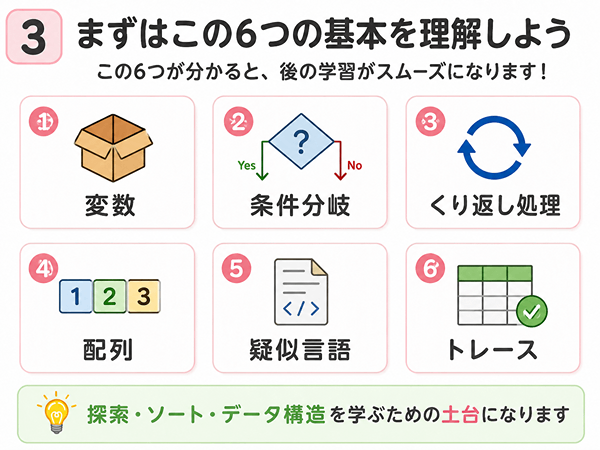
アルゴリズムを学ぶ前に、まず6つの基本を押さえると理解しやすくなります。
この6つは、探索、ソート、データ構造を学ぶ前の土台になります。
変数
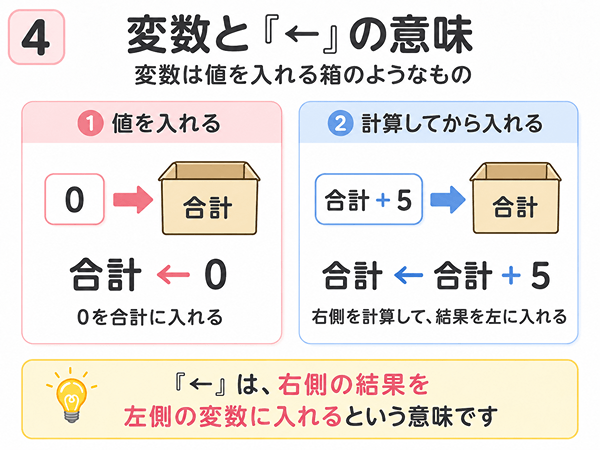
変数とは、値を入れておく箱のようなものです。
たとえば、点数、合計、人数、今見ている位置などを入れておけます。
点数 ← 80これは、「80を点数に入れる」という意味です。
あとから別の値を入れると、変数の中身は新しい値に変わります。
点数 ← 90この場合、点数の中身は90になります。
基本情報技術者試験では、変数の値が何に変わったかを追う問題がよく出ます。
条件分岐
条件分岐とは、条件によって処理を分けることです。
たとえば、点数が60点以上なら合格、60点未満なら不合格、という判断です。
もし 点数 が 60 以上 なら
結果 ← "合格"
そうでなければ
結果 ← "不合格"条件分岐では、どちらの道に進むのかを確認することが大切です。
条件を見落とすと、変数の値を間違えやすくなります。
くり返し処理
くり返し処理とは、同じ処理を何度も行うことです。
たとえば、5人分の点数を順番に合計する処理です。
商品を1件ずつ表示する、検索結果を1件ずつ確認する、点数を1つずつ足す、といった場面でも使います。
くり返し処理では、次の点を確認します。
- 何回くり返すか
- 毎回どの値が変わるか
- いつ終わるか
ループの終了条件を見落とすと、1回多く処理したり、1回少なく処理したりします。
配列

配列とは、複数のデータを順番に並べて持つ仕組みです。
たとえば、点数一覧、商品一覧、予約一覧、検索結果一覧などを扱うときに使います。
点数[1] ← 80
点数[2] ← 65
点数[3] ← 90この記事では、読みやすくするために「1番目、2番目、3番目」のように説明します。
ただし、プログラミング言語によっては、配列を0番目から数えることがあります。
また、基本情報技術者試験の問題では、問題文に配列の番号の前提が書かれます。
配列を読むときは、「今、何番目を見ているのか」を必ず確認しましょう。
配列とくり返し処理をまとめて確認したい方は、基本情報技術者試験の配列とループ入門も参考になります。
疑似言語
疑似言語とは、プログラムの処理を試験用に読みやすく書いたものです。
基本情報技術者試験では、この疑似言語を読んで処理を追います。
特に大切なのは、代入の記号です。
合計 ← 合計 + 点数[1]これは、「今の合計と点数[1]を足した結果を、合計に入れる」という意味です。
右側を先に計算し、その結果を左側に入れる、と読むと分かりやすくなります。
トレース

トレースとは、プログラムの処理を1行ずつ追いかけることです。
トレースでは、表を使うと分かりやすくなります。
| 手順 | 見ている処理 | 変数の値 | 配列の位置 |
|---|---|---|---|
| 1 | 合計 ← 0 | 合計は0 | – |
| 2 | 点数[1]を見る | 合計は0 | 1番目 |
| 3 | 合計 ← 合計 + 点数[1] | 合計は80 | 1番目 |
トレース表では、変数の値、配列の位置、くり返しの回数を追います。
頭の中だけで追うよりも、表に書いた方がミスを減らせます。
探索アルゴリズムの入口
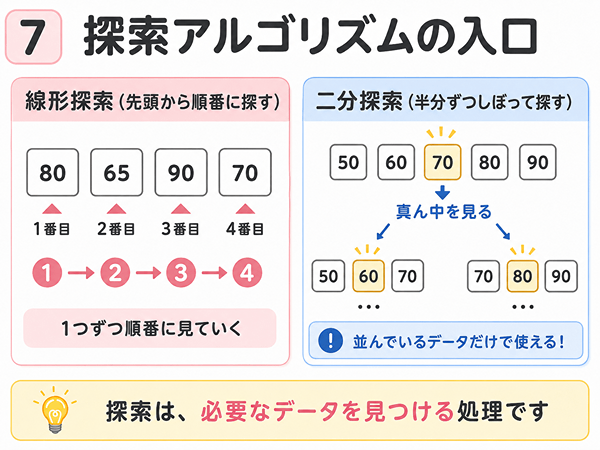
探索とは、必要なデータを探す処理です。
商品一覧から指定の商品を探す、会員番号から会員を探す、ファイル名からファイルを探す、といった場面で使います。
探索は必要なデータを探す処理
探索では、次のようなことを確認します。
- 何を探しているか
- どこから探し始めるか
- 今どのデータを見ているか
- 見つかったらどうするか
- 見つからなかったらどうするか
基本情報技術者試験では、探索の途中で「今どの位置を見ているか」を問われることがあります。
線形探索や二分探索の動きをくわしく確認したい方は、基本情報技術者試験の探索アルゴリズム入門も参考にしてください。
線形探索は先頭から順番に探す
線形探索は、データを先頭から順番に見ていく方法です。
たとえば、次の点数の中から90を探すとします。
点数[1] 80
点数[2] 65
点数[3] 90
点数[4] 70線形探索では、1番目、2番目、3番目のように順番に見ます。
3番目で90が見つかるので、そこで探す処理を終えます。
線形探索は分かりやすい方法です。
データが順番に並んでいなくても使えます。
二分探索は範囲を半分ずつしぼって探す
二分探索は、探す範囲を半分ずつしぼっていく方法です。
ただし、二分探索には大事な前提があります。
データが小さい順や大きい順に並んでいる必要があります。
たとえば、次のように点数が小さい順に並んでいる場合です。
点数[1] 50
点数[2] 60
点数[3] 70
点数[4] 80
点数[5] 90このように並んでいれば、真ん中の値を見て、探す値が左側にあるのか右側にあるのかを判断できます。
一方で、データが並んでいない場合、二分探索は正しく探せません。
「二分探索はいつでも速い」と覚えるのではなく、「並んでいるデータで使える」と理解しましょう。
探索は検索機能や会員情報の確認で使われる
探索の考え方は、身近な検索機能で使われます。
たとえば、会員番号を入力して会員情報を探すとき、裏側ではデータの中から一致するものを探しています。
ファイル検索や商品検索でも、同じように「条件に合うデータを探す」という考え方が使われます。
ソートアルゴリズムの入口
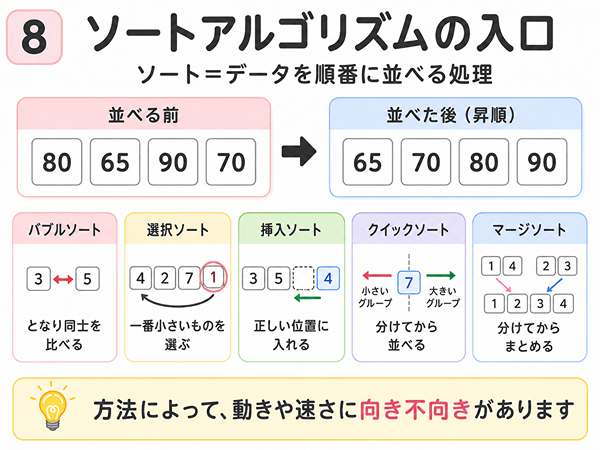
ソートとは、データを決まった順番に並べる処理です。
たとえば、価格が安い順、名前順、更新日順、点数が高い順などです。
ソートはデータを順番に並べる処理
ソートでは、データを比べながら順番を変えていきます。
たとえば、次の点数を小さい順に並べるとします。
80, 65, 90, 70小さい順に並べると、次のようになります。
65, 70, 80, 90このとき、どの値を比べるか、どの値を入れ替えるかが大切です。
価格順・名前順・更新日順で使われる
ソートは、身近なサービスでよく使われます。
- ネットショップの商品を価格順に並べる
- ファイルを更新日順に並べる
- 名簿を名前順に並べる
- テスト結果を点数順に並べる
- ランキングを順位順に並べる
画面では一瞬で並んで見えますが、裏側ではデータを比べる処理が行われています。
ソート方法によって向き不向きがある
ソートには、いくつかの方法があります。
- バブルソート
- 選択ソート
- 挿入ソート
- クイックソート
- マージソート
バブルソートは、となり同士を比べて入れ替える方法です。
選択ソートは、最小の値や最大の値を探して、決まった位置に置く方法です。
挿入ソートは、手札を並べるように、正しい位置へ入れていく方法です。
クイックソートは、基準になる値を使って、データを分けながら並べる方法です。
マージソートは、データを分けてから、順番にまとめる方法です。
どれがよいかは、データの数や並び方によって変わります。
ソートは「速い・遅い」だけでなく、「なぜそのデータに向いているのか」を見ることが大切です。
ソートの種類や動きをくわしく確認したい方は、基本情報技術者試験のソートアルゴリズム入門も参考にしてください。
データ構造の入口
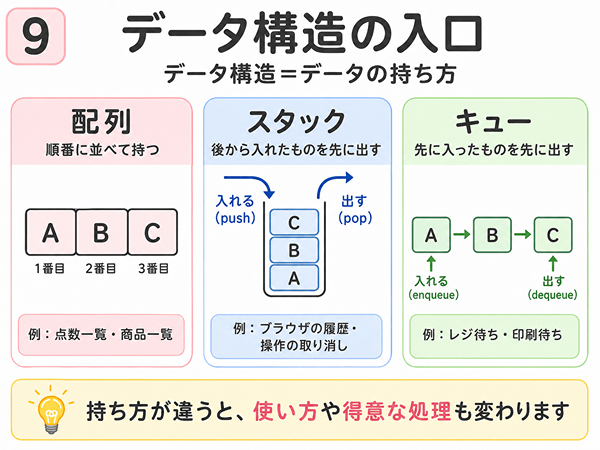
データ構造とは、データの持ち方です。
同じデータでも、持ち方が変わると、取り出しやすさや使いやすさが変わります。
データ構造はデータの持ち方
たとえば、書類を机の上にバラバラに置く場合と、ファイルに順番に入れる場合では、探しやすさが変わります。
プログラムでも同じです。
データをどう持つかによって、処理のしやすさが変わります。
配列は順番に並べて持つ
配列は、データを順番に並べて持つデータ構造です。
点数一覧、商品一覧、予約一覧など、順番に扱いたいデータに向いています。
商品[1] ← "りんご"
商品[2] ← "みかん"
商品[3] ← "バナナ"配列では、何番目のデータを見ているかが大切です。
教材画面では、今見ている配列の位置を強調すると、処理の流れが分かりやすくなります。
スタックは後から入れたものを先に出す
スタックは、後から入れたものを先に出すデータ構造です。
縦の筒にデータを入れるイメージです。
上から入れて、上から出します。
スタックに入れる操作をpush、取り出す操作をpopと呼びます。
身近な例では、ブラウザの戻るボタンや、操作の取り消しがあります。
最後に見たページへ戻る、最後に行った操作を取り消す、という動きはスタックの考え方に近いです。
キューは先に入れたものを先に出す
キューは、先に入ったものを先に出すデータ構造です。
横に並んだ列をイメージすると分かりやすいです。
先に並んだ人から順番に進みます。
キューに入れる操作をenqueue、取り出す操作をdequeueと呼びます。
身近な例では、印刷待ち、問い合わせ対応、レジ待ちがあります。
先に来たものから順番に処理する場面で使われます。
スタートボタンで処理の流れを見てみよう
ここでは、点数の配列を使って、処理の流れを1ステップずつ見てみます。
スタートを押すと、最初に合計へ0を入れるところから始まります。
次へボタンを押すと、1番目、2番目、3番目の点数を順番に見ながら、合計がどう変わるかを確認できます。
見るポイントは、次の3つです。
- 変数の値がどう変わるか
- 配列のどこを見ているか
- トレース表に何を書けばよいか
配列に入った点数を、左から順番に見て合計します。
「変数の値」「配列の位置」「トレース表」を1ステップずつ確認しましょう。
合計 ← 0
合計 ← 合計 + 点数[1]
合計 ← 合計 + 点数[2]
合計 ← 合計 + 点数[3]トレース表
| 手順 | 見ている処理 | 今見ている位置 | 点数 | 合計の変化 |
|---|---|---|---|---|
| 1 | 合計 ← 0 | – | – | 0に初期化 |
| 2 | 合計 ← 合計 + 点数[1] | 1番目 | 80 | 0 + 80 → 80 |
| 3 | 合計 ← 合計 + 点数[2] | 2番目 | 65 | 80 + 65 → 145 |
| 4 | 合計 ← 合計 + 点数[3] | 3番目 | 90 | 145 + 90 → 235 |
変数の値が変わる様子を見る
まずは、変数の値が変わる様子を見ます。
このミニシミュレーターでは、最初に合計へ0を入れます。
合計 ← 0そのあと、点数を1つずつ足していきます。
合計 ← 合計 + 点数[1]「今の合計」「今見ている点数」「足したあとの合計」を分けて見ると、処理の流れが分かりやすくなります。
大事なのは、変わった値を毎回確認することです。
配列のどこを見ているか確認する
次に、配列のどこを見ているかを確認します。
このミニシミュレーターでは、今見ている配列の位置に「今ここ」と表示されます。
たとえば、点数[2]を見ているときは、「2番目を見ている」と分かるようになっています。
ここで注意したいのが、配列の番号ずれです。
本文や教材画面では、初心者に分かりやすいように「1番目、2番目」と表示しています。
ただし、JavaScriptなどのプログラム内部では、配列を0から数えることがあります。
また、基本情報の問題では、問題文に書かれた配列番号の前提を確認することが大切です。
ループで同じ処理がくり返される様子を見る
ループでは、同じ処理が何度も行われます。
このミニシミュレーターでは、次へボタンを押すたびに、見ている点数と合計が変わります。
たとえば、点数を3つ合計する場合は、次のように変わります。
| 回数 | 見ている点数 | 合計の変化 |
|---|---|---|
| 1回目 | 80 | 0 + 80 → 80 |
| 2回目 | 65 | 80 + 65 → 145 |
| 3回目 | 90 | 145 + 90 → 235 |
このように、値の変化を見える形にすると、処理の流れを追いやすくなります。
探索やソートの教材では、比較回数や交換回数を見ることで、なぜその処理をしているのかを理解しやすくなります。
基本情報技術者試験ではアルゴリズムがどう出る?
基本情報技術者試験では、アルゴリズムがいろいろな形で出ます。
ただし、中心になるのは「処理を追う力」です。
疑似言語を読んで処理を追う問題
疑似言語を読んで、処理がどう進むかを考える問題があります。
このときは、1行ずつ見ていきます。
先に全体を何となく読むのではなく、変数の値が変わる場所を確認しましょう。
変数の値を問う問題
処理のあと、変数の値がいくつになるかを問う問題があります。
たとえば、合計、個数、最大値、最小値、今見ている位置などです。
変数は途中で何度も更新されることがあります。
そのため、更新された値をトレース表に書くことが大切です。
配列の中身を問う問題
配列の中身がどう変わるかを問う問題もあります。
特にソートでは、値を入れ替えるため、配列の中身が途中で変わります。
どの位置とどの位置を比べたのか、どこを入れ替えたのかを追う必要があります。
ループの回数を問う問題
ループが何回行われるかを問う問題があります。
このときは、開始の値、終了条件、1回ごとの変化を確認します。
終了条件の「以上」「以下」「未満」を見落とさないようにしましょう。
探索やソートの動きを問う問題
探索やソートでは、途中の状態を問われることがあります。
探索では、今見ている位置、探す範囲、比較回数を確認します。
ソートでは、比較した値、入れ替えた値、どこまで確定したかを確認します。
途中の状態を追えるようになると、選択肢をしぼりやすくなります。
初心者がつまずきやすい点
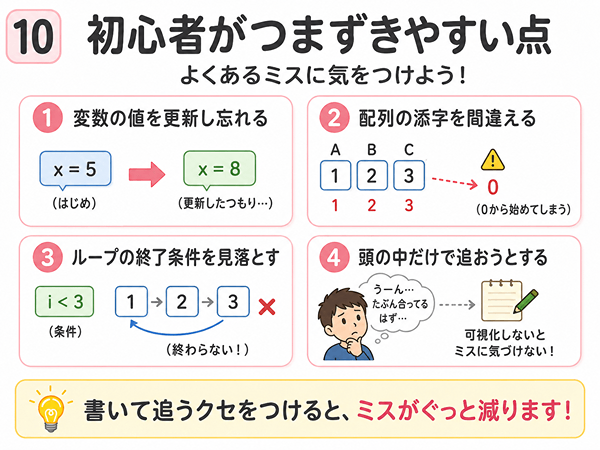
アルゴリズム学習では、つまずきやすい点があります。
先に知っておくと、問題を読むときに気づきやすくなります。
変数の値を更新し忘れる
変数は、処理の途中で値が変わります。
たとえば、合計に点数を足したら、合計の値は新しくなります。
古い値のまま考えると、答えがずれます。
代入が出てきたら、変数の値を書き直しましょう。
配列の添字を間違える
添字とは、配列の何番目かを表す番号です。
たとえば、点数[1]なら1番目、点数[2]なら2番目という意味です。
ただし、問題やプログラミング言語によって、番号の始まり方が違うことがあります。
本文や教材画面では「1番目、2番目」と表示すると分かりやすいですが、実際の試験では、問題文の前提を必ず確認しましょう。
ループの終了条件を見落とす
ループでは、いつ終わるかが大切です。
終了条件を見落とすと、処理の回数を間違えます。
特に、「5未満」と「5以下」は意味が違います。
5未満は5を含みません。5以下は5を含みます。
この違いで、処理回数が変わることがあります。
頭の中だけで処理を追おうとする
アルゴリズムの問題を、頭の中だけで追うのは大変です。
最初のうちは、必ず表やメモを使いましょう。
変数の値、配列の位置、ループの回数を書きながら進めると、ミスを減らせます。
基本情報技術者試験では、速く読むことよりも、正しく追うことが大切です。
おすすめの学習順
アルゴリズムは、順番に学ぶと理解しやすくなります。
いきなりソートやデータ構造に入るよりも、まず処理を読むための土台を作りましょう。
まず疑似言語とトレースを理解する
最初に、疑似言語の読み方とトレースを理解します。
「←」の意味、変数の更新、条件分岐、ループの流れを押さえます。
ここが分かると、あとの学習が進めやすくなります。
次に配列とループを理解する
次に、配列とループを学びます。
基本情報技術者試験のアルゴリズム問題では、配列とループがよく組み合わされます。
配列の何番目を見ているか、ループで何回処理しているかを確認できるようにしましょう。
探索で探す処理を理解する
その次に、探索を学びます。
線形探索では、先頭から順番に探す動きを確認します。
二分探索では、データが並んでいることを前提に、範囲を半分ずつしぼる動きを確認します。
今見ている位置、探索範囲、比較回数を追うことが大切です。
ソートで並べる処理を理解する
探索の次は、ソートを学びます。
ソートでは、どの値を比べたか、どの値を入れ替えたか、どこまで並びが決まったかを見ます。
同じ初期データで、いくつかのソート方法を比べると違いが分かりやすくなります。
最後にデータ構造を整理する
最後に、データ構造を整理します。
配列、リスト、スタック、キューなどは、データの持ち方が違います。
スタックは後から入れたものを先に出します。
キューは先に入ったものを先に出します。
配列、リスト、スタック、キューの違いをくわしく確認したい方は、基本情報技術者試験のデータ構造入門も参考になります。
それぞれの違いを、身近な例とセットで覚えると理解しやすくなります。
確認問題
最後に、この記事の内容を確認しましょう。
問題1
アルゴリズムとは、かんたんに言うと何ですか。
- A. コンピューターの部品
- B. 問題を解くための手順
- C. 画面のデザイン
- D. インターネットの回線
答えは、Bです。
アルゴリズムは、問題を解くための手順です。
問題2
基本情報技術者試験の疑似言語で、次の処理は何を意味しますか。
合計 ← 0- A. 合計と0を比べる
- B. 合計から0を引く
- C. 0を合計に入れる
- D. 合計を表示する
答えは、Cです。
「←」は、右側の値を左側の変数に入れる意味です。
問題3
二分探索を使うときに必要な前提はどれですか。
- A. データが順番に並んでいる
- B. データがすべて同じ値である
- C. データが1件だけである
- D. データが文字だけである
答えは、Aです。
二分探索は、データが順番に並んでいることが前提です。
問題4
トレースで主に確認するものとして正しいものはどれですか。
- A. 画面の色
- B. 変数の値や配列の位置
- C. パソコンの値段
- D. ネット回線の速さ
答えは、Bです。
トレースでは、変数の値、配列の位置、ループの回数などを追います。
まとめ
アルゴリズムは、問題を解くための手順です。
基本情報技術者試験の科目Bでは、アルゴリズムの名前を覚えるだけではなく、処理の流れを追う力が大切です。
まずは、変数、条件分岐、くり返し処理、配列、疑似言語、トレースを理解しましょう。
そのうえで、探索、ソート、データ構造へ進むと、学習しやすくなります。
疑似言語では、代入を「←」で表します。
「←」は、右側の計算結果を左側の変数に入れるという意味です。
配列では、今何番目を見ているのかを確認することが大切です。
また、問題文によって配列の番号の始まり方が違うことがあります。
配列を読むときは、問題文の前提を必ず確認しましょう。
アルゴリズムは、頭の中だけで追うと難しく感じます。
トレース表を使って、1ステップずつ処理を追うことで、基本情報技術者試験の問題にも取り組みやすくなります。