
探索アルゴリズムとは、たくさんのデータの中から、目的のデータを探すための手順です。
基本情報技術者試験では、探索の名前を覚えるだけでは足りません。どの順番でデータを見るのか、何回比べるのか、見つからないときにどうなるのかを追う力が大切です。
科目B全体の進め方を確認したい方は、基本情報技術者試験の科目B対策も参考にしてください。
この記事では、線形探索と二分探索を中心に、探索の動きを順番に説明します。ハッシュ探索は、考え方の入口だけを扱います。
探索アルゴリズムは何をするもの?

探索は必要なデータを探す処理
探索は、データの中から必要なものを見つける処理です。
たとえば、商品一覧から「りんご」を探す、会員番号から会員情報を探す、フォルダの中から目的のファイルを探す。これらはすべて探索の考え方です。
プログラムでは、データが1件だけとは限りません。10件、100件、1万件の中から目的の値を探すことがあります。そのときに使う手順が、探索アルゴリズムです。
アルゴリズム全体の考え方を先に確認したい方は、基本情報技術者試験のアルゴリズム入門も参考になります。
データの中から目的の値を見つける
探索では、探したい値を決めます。
たとえば、次のデータから「30」を探すとします。
| 何番目 | 1番目 | 2番目 | 3番目 | 4番目 | 5番目 |
|---|---|---|---|---|---|
| 値 | 10 | 40 | 30 | 20 | 50 |
この場合、30は3番目にあります。
探索アルゴリズムでは、「どの順番で見るか」「見つかったらどうするか」「見つからなかったらどうするか」を決めます。
探し方によって効率が変わる
探し方には、いくつかの種類があります。
先頭から1つずつ見る方法もあります。データが順番に並んでいることを利用して、真ん中から探す方法もあります。
同じ値を探す場合でも、探し方によって、見る回数が大きく変わります。
たとえば、100件の中から探すとき、先頭から順番に見ると多くの回数が必要になることがあります。ところが、データが小さい順に並んでいれば、二分探索によって少ない回数で見つけられることがあります。
なぜ探索を学ぶの?
データを探す処理は多くのシステムで使われる
探索は、多くのシステムで使われます。
ショッピングサイトでは、商品を探します。学校のシステムでは、学生番号から学生情報を探します。会社のシステムでは、社員番号から社員情報を探します。
つまり、探索は「データを使うシステム」の基本です。
探索を学ぶと、検索機能の裏側で何が起きているのかをイメージしやすくなります。
探し方によって速さが大きく変わる
データが少ないときは、どの探し方でも大きな差は出にくいです。
しかし、データが多くなると、探し方の差が目立ちます。
たとえば、10件なら先頭から見てもすぐです。けれども、100万件の中から探す場合、毎回先頭から順番に見ると時間がかかります。
そのため、データの状態に合った探し方を選ぶことが大切です。
基本情報技術者試験では処理の流れを問われやすい
基本情報技術者試験では、「探索アルゴリズムの名前を答える」だけではなく、処理の途中を問われることがあります。
たとえば、次のような問題です。
- 何回比較するか
- 次にどの位置を見るか
- 探索範囲がどう変わるか
- 見つからない場合、どの条件で処理を終えるか
- 空欄に入る処理はどれか
そのため、探索は「流れを目で追う」ことが大切です。
探索は身近で何に使われる?
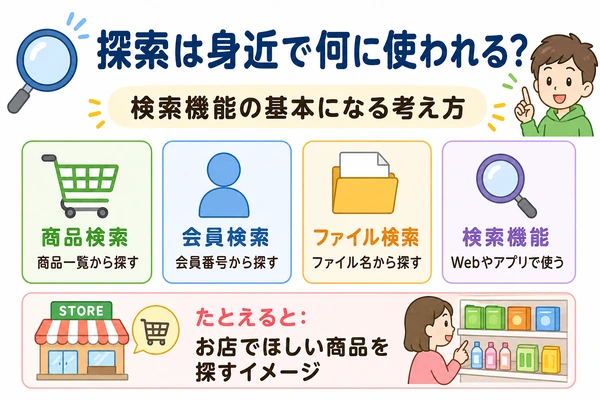
商品一覧から目的の商品を探す
ネットショップで商品を探すとき、システムは商品データの中から条件に合うものを探します。
商品名、カテゴリ、価格、在庫の有無などをもとに、目的の商品を見つけます。
このとき、データの中から必要なものを探す考え方が使われます。
会員番号から会員情報を探す
会員番号を入力して、名前や住所を表示する仕組みでも探索が使われます。
たとえば、会員番号「1003」の人を探す場合、会員データの中から「1003」に合うデータを見つけます。
番号が順番に並んでいるなら、二分探索のように範囲をしぼる考え方が使えます。
ファイル名からファイルを探す
パソコンやスマホでファイル名を検索するときも、探索の考え方が関係します。
フォルダの中にたくさんのファイルがある場合、目的のファイル名に合うものを探します。
データを1つずつ見るのか、整理された情報を使って効率よく探すのかで、探す速さが変わります。
検索機能の基本になる考え方
探索は、検索機能を理解するための入口です。
実際の検索システムはもっと複雑です。けれども、基本の考え方は「たくさんのデータから目的に合うものを見つける」ことです。
探索アルゴリズムを学ぶと、検索がただの魔法ではなく、手順に沿って動く処理だと分かります。
線形探索とは?

先頭から順番に探す方法
線形探索は、データを先頭から順番に見ていく方法です。
たとえば、次のデータから「30」を探します。
| 何番目 | 1番目 | 2番目 | 3番目 | 4番目 | 5番目 |
|---|---|---|---|---|---|
| 値 | 10 | 40 | 30 | 20 | 50 |
線形探索では、次のように見ます。
- 1番目の10を見る
- 30ではないので、次へ進む
- 2番目の40を見る
- 30ではないので、次へ進む
- 3番目の30を見る
- 探していた値なので、見つかったとする
このように、前から順番に確認するのが線形探索です。
データが並んでいなくても使える
線形探索のよい点は、データが並んでいなくても使えることです。
次のように、数字がばらばらでも使えます。
| 何番目 | 1番目 | 2番目 | 3番目 | 4番目 | 5番目 |
|---|---|---|---|---|---|
| 値 | 40 | 10 | 50 | 30 | 20 |
順番に見ていけば、いつか目的の値にたどり着けます。
そのため、線形探索は分かりやすく、使いやすい方法です。
仕組みは分かりやすい
線形探索は、日常の探し方に近いです。
たとえば、名前が書かれた紙の束から、目的の名前を上から1枚ずつ確認するイメージです。
見つかればそこで終わります。最後まで見てもなければ、「見つからない」と判断します。
データが多いと時間がかかりやすい
線形探索は分かりやすい方法ですが、データが多いと時間がかかりやすいです。
目的の値が先頭にあれば、すぐ見つかります。
しかし、目的の値が最後にある場合は、最後まで見ないと見つかりません。目的の値がない場合も、最後まで見る必要があります。
つまり、データが多いほど、比較回数が増えやすい方法です。
二分探索とは?

真ん中を見て範囲を半分にする方法
二分探索は、データの真ん中を見て、探す範囲を半分にしながら探す方法です。
たとえば、次のように小さい順に並んだデータから「70」を探します。
| 何番目 | 1番目 | 2番目 | 3番目 | 4番目 | 5番目 | 6番目 | 7番目 |
|---|---|---|---|---|---|---|---|
| 値 | 10 | 20 | 30 | 40 | 50 | 60 | 70 |
最初に真ん中の4番目を見ます。
4番目は40です。探している70は40より大きいので、左側を見る必要はありません。
次は、右側の範囲だけを見ます。
このように、見る範囲を半分ずつ減らしていくのが二分探索です。
データが並んでいるときに使える
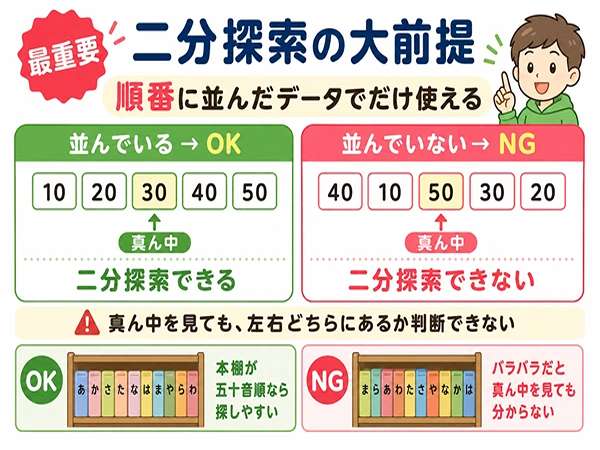
二分探索は、データが順番に並んでいることが前提です。
小さい順、または大きい順に並んでいるからこそ、「真ん中より大きいなら右側にある」「真ん中より小さいなら左側にある」と判断できます。
データが並んでいない場合、この判断はできません。
たとえば、次のようにばらばらに並んでいるデータでは、真ん中を見ても左右のどちらにあるか分かりません。
| 何番目 | 1番目 | 2番目 | 3番目 | 4番目 | 5番目 |
|---|---|---|---|---|---|
| 値 | 50 | 10 | 40 | 20 | 30 |
そのため、二分探索を使う前には、データが順番に並んでいるかを必ず確認します。
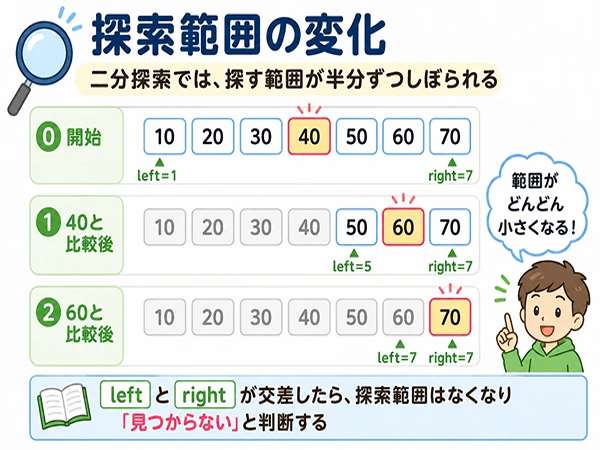
探す範囲がどんどん狭くなる
二分探索では、最初に全体を探索範囲にします。
真ん中の値を見て、目的の値が左側にあるか、右側にあるかを判断します。
不要な半分を捨てるので、探索範囲がどんどん狭くなります。
この「範囲をしぼる動き」が、二分探索の大事なポイントです。
線形探索より少ない回数で見つけやすい
二分探索は、条件が合えば少ない比較回数で見つけやすい方法です。
たとえば、データが多くても、毎回見る範囲を半分にできます。
ただし、いつでも二分探索がよいわけではありません。
二分探索を使うには、データが順番に並んでいる必要があります。並んでいないデータでは、線形探索の方が正しく探せます。
ハッシュ探索とは?
キーから保存場所を計算して探す方法
ハッシュ探索は、キーから保存場所を計算して探す考え方です。
キーとは、データを探すための手がかりになる値です。たとえば、会員番号、社員番号、商品コードなどです。
ハッシュ探索では、キーをもとに「どこに保存されているか」を計算します。
線形探索のように先頭から順番に見るのではなく、目的の場所に近いところへ直接行くイメージです。
うまく使えれば、データが多い場合でも少ない手順で目的のデータを探しやすい点が強みです。
会員番号やIDで探す考え方に近い
会員番号やIDでデータを探す仕組みは、ハッシュ探索の考え方に近いです。
たとえば、会員番号を入力すると、その番号をもとに会員情報を探します。
実際のシステムでは、ハッシュ表というデータの持ち方が使われることがあります。
この記事では、ハッシュ探索は「キーから保存場所を求める探し方」と押さえておけば十分です。
基本情報技術者試験では考え方を押さえる
基本情報技術者試験では、ハッシュ探索の細かい仕組みよりも、考え方を問われることがあります。
ポイントは、次の3つです。
- キーを使って探す
- 保存場所を計算する考え方がある
- 線形探索とは探し方が違う
まずは、線形探索と二分探索をしっかり理解しましょう。その上で、ハッシュ探索は別の探し方として押さえます。
スタートボタンで探索の動きを見る
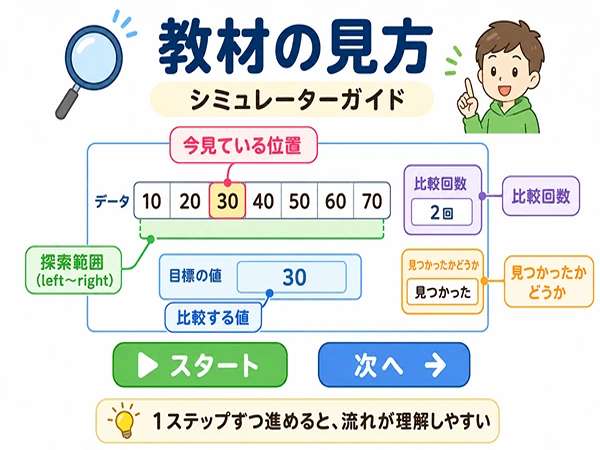
この記事では、HTML/JavaScriptの教材を入れる前提で、探索の動きを見ながら理解します。
教材では、スタートボタンを押すと探索が始まります。次へボタンを押すと、1ステップずつ処理を確認できます。
見るポイントは、次の5つです。
- 今見ている位置
- 今見ている値
- 探索範囲
- 比較回数
- 見つかったかどうか
探索アルゴリズムを動かして見てみよう
スタートボタンで自動再生、次へボタンで1ステップずつ確認できます。今見ている位置、探索範囲、比較回数に注目しましょう。
線形探索で先頭から順番に探す
線形探索の教材では、1番目から順番に値を見ていきます。
今見ている位置が強調されるので、「次はどこを見るのか」を確認します。
たとえば、探す値が30なら、教材では次のように動きます。
- 1番目を見る
- 探す値と同じか比べる
- 違えば2番目へ進む
- 同じ値が見つかれば終了する
ここでは、比較回数も見ます。
比較回数とは、探している値とデータを何回比べたかを表す数です。
二分探索で範囲を半分にする
二分探索の教材では、探索範囲が大事です。
最初は、データ全体が探索範囲です。
真ん中の値を見て、探す値が小さければ左側を残します。探す値が大きければ右側を残します。
次へボタンを押すたびに、探索範囲が狭くなる様子を確認します。
ここで大切なのは、二分探索はデータが並んでいるときだけ正しく動くことです。
教材では、ランダムなデータで二分探索を動かそうとした場合、「並んでいないため正しく探せない」という注意を表示する想定です。
今見ている位置を確認する
探索では、「今どこを見ているか」を追うことが大切です。
線形探索では、1番目、2番目、3番目のように順番に進みます。
二分探索では、真ん中を見ます。その後、残った範囲の真ん中を見ます。
教材画面では、今見ている配列の位置を強調します。
本文や教材では、初心者が分かりやすいように「1番目、2番目、3番目」と表示します。
ただし、プログラムの内部や試験問題では、配列の番号が0から始まる場合もあります。問題文で「配列の添字がどこから始まるか」を必ず確認しましょう。
比較回数を確認する
比較回数は、探索の手間を知るための目安です。
線形探索では、先頭から順番に比べるので、目的の値が後ろにあるほど比較回数が増えます。
二分探索では、真ん中を見て範囲をしぼるので、比較回数が少なくなりやすいです。
ただし、二分探索は並んだデータが前提です。比較回数だけを見て「いつでも二分探索がよい」と考えないようにしましょう。
同じデータで線形探索と二分探索を比べる
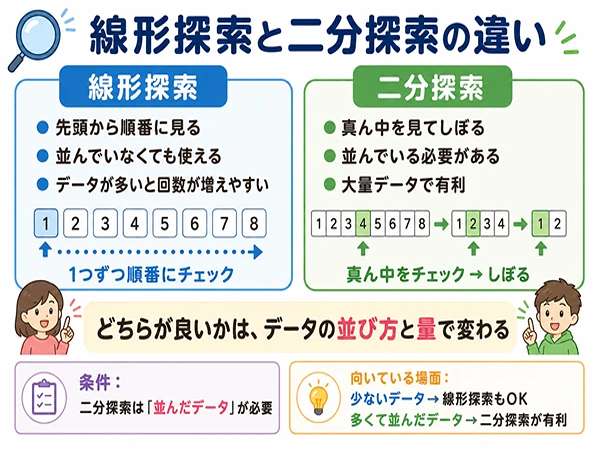
線形探索と二分探索は、同じデータで比べると違いが分かりやすくなります。
教材では、同じデータを使って、線形探索と二分探索の動きを見比べます。
ランダムなデータで比べる
ランダムなデータとは、順番に並んでいないデータのことです。
たとえば、次のようなデータです。
| 何番目 | 1番目 | 2番目 | 3番目 | 4番目 | 5番目 |
|---|---|---|---|---|---|
| 値 | 40 | 10 | 50 | 30 | 20 |
この場合、線形探索は使えます。先頭から順番に見れば、目的の値を探せます。
一方、二分探索は正しく使えません。データが並んでいないため、真ん中を見ても、左に行くべきか右に行くべきか判断できないからです。
教材では、この場合に二分探索を始めず、「並んでいないため正しく探せない」と表示する想定です。
昇順に並んだデータで比べる
昇順とは、小さい値から大きい値へ順番に並んでいることです。
たとえば、次のようなデータです。
| 何番目 | 1番目 | 2番目 | 3番目 | 4番目 | 5番目 | 6番目 | 7番目 |
|---|---|---|---|---|---|---|---|
| 値 | 10 | 20 | 30 | 40 | 50 | 60 | 70 |
この場合は、線形探索も二分探索も使えます。
線形探索は1番目から順番に見ます。
二分探索は真ん中を見て、探索範囲を半分にします。
教材では、同じ値を探して、比較回数がどう変わるかを見ます。
探す値が先頭にある場合
探す値が先頭にある場合、線形探索はすぐ見つけられます。
たとえば、1番目にある10を探すなら、線形探索は1回の比較で見つけられます。
二分探索は、まず真ん中を見るため、必ずしも1回で見つかるとは限りません。
このように、いつでも二分探索の方が少ない回数になるとは限りません。
探す値が最後にある場合
探す値が最後にある場合、線形探索は最後まで見る必要があります。
7件のデータなら、7番目まで比べることがあります。
二分探索では、真ん中を見て右側に範囲をしぼります。そのため、少ない回数で見つかることがあります。
データが多いほど、この差は大きくなりやすいです。
探す値がない場合
探す値がない場合も大切です。
線形探索では、最後まで見ても見つからなければ「ない」と判断します。
二分探索では、探索範囲がなくなったら「ない」と判断します。
基本情報技術者試験では、この「見つからない場合の終了条件」が問われることがあります。
探索アルゴリズムの向き不向き
線形探索はデータが少ないときに分かりやすい
線形探索は、処理の流れがとても分かりやすいです。
データが少ないときは、先頭から順番に見ても大きな負担になりません。
そのため、小さなデータを扱う場合や、まず考え方を理解する場面に向いています。
線形探索は並んでいないデータでも使える
線形探索の強みは、データが並んでいなくても使えることです。
商品一覧、名前の一覧、入力されたばかりのデータなど、順番が整っていない場合でも探せます。
ただし、データが多い場合は、比較回数が増えやすい点に注意します。
二分探索は並んだデータに向いている
二分探索は、データが順番に並んでいるときに向いています。
小さい順や大きい順に並んでいれば、真ん中の値を見て、どちら側に探す値があるか判断できます。
逆に、並んでいないデータでは使えません。
二分探索は「速い方法」とだけ覚えるのではなく、「並んだデータで使える方法」と覚えましょう。
二分探索は大量データで効果が出やすい
二分探索は、データが多いほど効果が出やすいです。
毎回、探索範囲を半分にできるからです。
たとえば、データが100件、1,000件、10,000件と増えても、見る回数を大きく減らせます。
ただし、先にデータを並べる必要があります。すでに並んでいるデータなら、二分探索の強みを使いやすくなります。
疑似言語ではどう書く?
基本情報技術者試験の疑似言語では、代入を「←」で表します。
「←」は、右側の値や計算結果を、左側の変数に入れるという意味です。
たとえば、次のように読みます。
i ← 1これは、「iに1を入れる」という意味です。
線形探索の疑似言語
線形探索は、先頭から順番に見ます。
次は、配列 data から target を探す例です。ここでは、説明を分かりやすくするため、配列は1番目からn番目まであるものとして書きます。
配列とループの基本に不安がある方は、基本情報技術者試験の配列とループ入門も確認しておくと理解しやすくなります。
found ← false
position ← 0
i を 1 から n まで 1 ずつ増やす
もし data[i] が target と同じなら
found ← true
position ← i
繰り返しを終える
もし終わり
繰り返し終わりfound は、見つかったかどうかを表す変数です。
position は、見つかった位置を表す変数です。
最初はまだ見つかっていないので、found に false を入れます。見つかったら found に true を入れます。
二分探索の疑似言語
二分探索では、左端、右端、真ん中を使います。
左端は、探索範囲のいちばん左の位置です。右端は、探索範囲のいちばん右の位置です。真ん中は、その範囲の中央の位置です。
left ← 1
right ← n
found ← false
position ← 0
left が right 以下の間、繰り返す
mid ← (left + right) ÷ 2 の整数部分
もし data[mid] が target と同じなら
found ← true
position ← mid
繰り返しを終える
そうでなく、data[mid] が target より小さいなら
left ← mid + 1
そうでなければ
right ← mid - 1
もし終わり
繰り返し終わりmid は、探索範囲の真ん中です。
data[mid] が target より小さい場合、探す値は右側にあると判断します。そのため、left を mid の次に動かします。
data[mid] が target より大きい場合、探す値は左側にあると判断します。そのため、right を mid の前に動かします。
添字と探索範囲の見方
添字とは、配列の何番目かを表す番号です。
初心者が間違えやすいのは、配列の番号の始まりです。
この記事の説明では「1番目、2番目、3番目」と書いています。これは、初心者が画面で見て分かりやすくするためです。
一方、プログラムや試験問題では、配列の添字が0から始まることがあります。
たとえば、1番目のデータを data[0] と表す場合があります。
そのため、基本情報技術者試験の問題では、問題文に書かれた配列番号の前提を必ず確認します。
二分探索では、特に left、right、mid の位置を間違えやすいです。今の探索範囲が何番目から何番目までなのかを、毎回確認しましょう。
トレース表で探索を追う
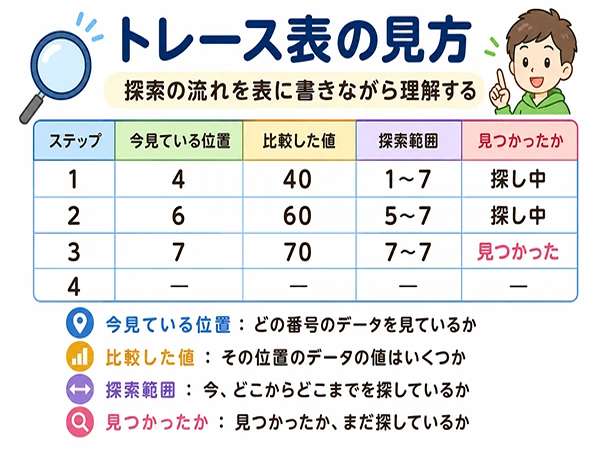
トレース表とは、処理の途中で変数や配列の値がどう変わるかを書き出す表です。
探索では、頭の中だけで追うと混乱しやすいです。表にすると、今どこを見ているかが分かりやすくなります。
トレースの基本から確認したい方は、基本情報技術者試験の疑似言語とトレース入門も参考にしてください。
今見ている位置を書く
まず、今見ている位置を書きます。
線形探索なら、1番目、2番目、3番目のように進みます。
二分探索なら、mid の位置を書きます。
| 回数 | 今見ている位置 | 今見ている値 |
|---|---|---|
| 1回目 | 4番目 | 40 |
| 2回目 | 6番目 | 60 |
このように書くと、どの順番で見たかが分かります。
比較した値を書く
次に、比較した値を書きます。
探索では、今見ている値と探す値を比べます。
たとえば、探す値が70で、今見ている値が40なら、「70は40より大きい」と判断します。
| 回数 | 今見ている値 | 探す値 | 判断 |
|---|---|---|---|
| 1回目 | 40 | 70 | 70は40より大きい |
| 2回目 | 60 | 70 | 70は60より大きい |
判断を書いておくと、次にどちらへ進むのかが分かりやすくなります。
探索範囲を書く
二分探索では、探索範囲を書くことがとても大切です。
left と right が変わるたびに、範囲が変わります。
| 回数 | left | right | mid | data[mid] | 判断 |
|---|---|---|---|---|---|
| 1回目 | 1番目 | 7番目 | 4番目 | 40 | 右側を探す |
| 2回目 | 5番目 | 7番目 | 6番目 | 60 | 右側を探す |
| 3回目 | 7番目 | 7番目 | 7番目 | 70 | 見つかった |
この表を見ると、探索範囲が狭くなっていることが分かります。
見つかったかどうかを書く
最後に、見つかったかどうかを書きます。
見つかった場合は、見つかった位置を書きます。
見つからない場合は、最後まで探したのか、探索範囲がなくなったのかを書きます。
| 結果 | 意味 |
|---|---|
| 見つかった | 探す値と同じ値があった |
| 見つからない | 探す値と同じ値がなかった |
基本情報技術者試験では、見つからない場合の処理もよく問われます。
基本情報技術者試験ではどう出る?
何回比較するかを問う問題
探索では、比較回数を問われることがあります。
線形探索なら、目的の値が何番目にあるかで比較回数が決まります。
たとえば、5番目にある値を探すなら、先頭から5回比べることがあります。
二分探索なら、mid を何回見たかを数えます。
比較回数を数えるときは、「値を見た回数」を落ち着いて数えましょう。
どの位置を見るかを問う問題
次にどの位置を見るかを問う問題もあります。
線形探索では、基本的に次の位置へ進みます。
二分探索では、真ん中を見たあと、左側か右側に範囲をしぼります。
このとき、mid の計算と、left、right の更新を間違えないことが大切です。
二分探索の探索範囲を問う問題
二分探索では、探索範囲がどう変わるかを問われやすいです。
data[mid] が target より小さいなら、左側とmidはもう調べる必要がありません。
そのため、left を mid の次に動かします。
data[mid] が target より大きいなら、右側とmidはもう調べる必要がありません。
そのため、right を mid の前に動かします。
この範囲の更新が、二分探索の中心です。
空欄に入る条件を選ぶ問題
疑似言語の一部が空欄になり、正しい条件を選ぶ問題もあります。
たとえば、次のような条件です。
- data[mid] が target と同じか
- data[mid] が target より小さいか
- left が right 以下か
- 見つかったら処理を終えるか
空欄問題では、前後の処理を見ます。
「この条件が成り立ったら、次に何をしたいのか」を考えると、選びやすくなります。
初心者が間違えやすい点
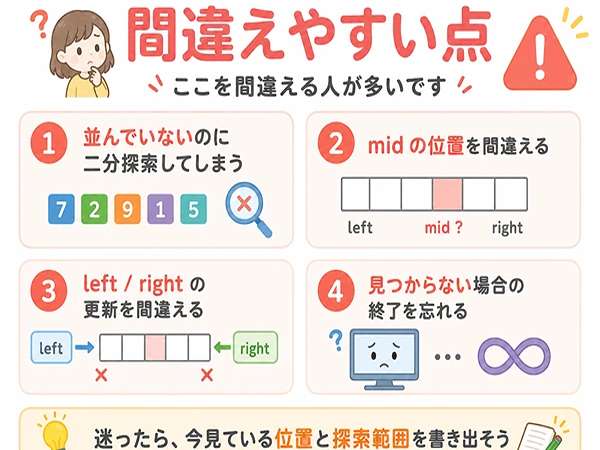
二分探索は並んでいないデータでは使えないことを忘れる
二分探索でいちばん大切なのは、データが並んでいることです。
並んでいないデータでは、真ん中を見ても、左側にあるのか右側にあるのか判断できません。
そのため、二分探索を使う前に、データが昇順や降順に並んでいるかを確認します。
「二分探索は速い」とだけ覚えると間違えやすいです。
正しくは、「二分探索は、並んだデータに対して範囲を半分にしながら探す方法」です。
mid の位置を間違える
mid は、探索範囲の真ん中です。
データ全体の真ん中ではなく、今の left から right までの範囲の真ん中です。
探索が進むと、left と right は変わります。
そのため、mid も毎回変わります。
mid を求めるときは、今の探索範囲を確認してから考えましょう。
探索範囲の更新を間違える
二分探索では、left と right の更新を間違えやすいです。
data[mid] が target より小さい場合、探す値は右側にあります。
そのため、left ← mid + 1 とします。
data[mid] が target より大きい場合、探す値は左側にあります。
そのため、right ← mid – 1 とします。
mid をもう一度含めてしまうと、同じ位置を何度も見ることがあります。更新後の範囲に注意しましょう。
見つからない場合の処理を忘れる
探索では、見つかる場合だけでなく、見つからない場合も考えます。
線形探索では、最後まで見てもなければ「見つからない」とします。
二分探索では、left が right を超えて探索範囲がなくなったら「見つからない」とします。
基本情報技術者試験では、見つからないときの終了条件を問われることがあります。
「見つかったら終わり」だけでなく、「見つからないときはどこで終わるか」も確認しましょう。
確認問題
線形探索はどのように探しますか?
線形探索は、データを先頭から順番に見て、探す値と同じかどうかを比べる方法です。
見つかればそこで終わります。最後まで見てもなければ、見つからないと判断します。
二分探索を使う前提は何ですか?
二分探索を使う前提は、データが順番に並んでいることです。
小さい順や大きい順に並んでいるからこそ、真ん中を見て、左側を探すか右側を探すかを判断できます。
並んでいないデータでは、二分探索は正しく使えません。
探索範囲はどのように変わりますか?
二分探索では、真ん中の値を見て、探索範囲を半分にしぼります。
探す値が真ん中の値より大きければ、右側を残します。
探す値が真ん中の値より小さければ、左側を残します。
このように、探索範囲が少しずつ狭くなります。
まとめ
探索アルゴリズムは、たくさんのデータの中から目的の値を探すための手順です。
線形探索は、先頭から順番に探す方法です。データが並んでいなくても使えますが、データが多いと比較回数が増えやすくなります。
二分探索は、真ん中を見て探索範囲を半分にしながら探す方法です。少ない回数で見つけやすい方法ですが、データが順番に並んでいることが前提です。
ハッシュ探索は、キーから保存場所を計算して探す考え方です。会員番号やIDでデータを探す仕組みに近い考え方として押さえておきましょう。
基本情報技術者試験では、探索の名前だけでなく、処理の流れを追う力が問われます。
特に、今見ている位置、比較回数、探索範囲、見つからない場合の処理を確認することが大切です。
探索は、暗記だけで覚えるよりも、実際に動きを見ながら学ぶ方が理解しやすいです。スタートボタンや次へボタンで1ステップずつ確認し、どの値を見て、なぜ次の範囲へ進むのかを追っていきましょう。
データを並べ替える処理もあわせて確認したい方は、基本情報技術者試験のソートアルゴリズム入門も参考にしてください。